Why modern software teams moved from “it works on my machine” to self-healing infrastructure.
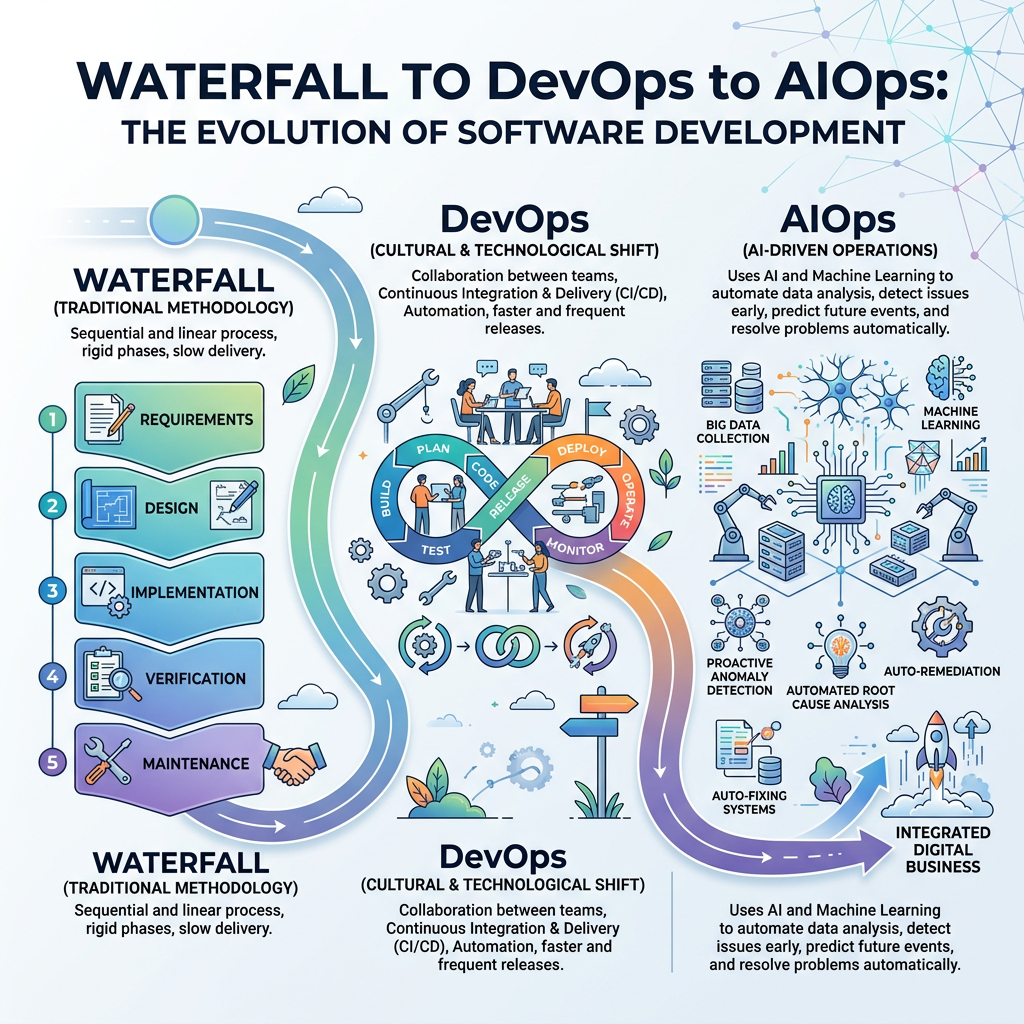
The image illustrates the transition from traditional Waterfall methodology to modern DevOps and AIOps in software development.
Introduction
There was a time when software delivery teams spent more time blaming each other than solving problems.
Developers would say:
“It works perfectly on my machine.”
Operations teams would respond:
“Then why is production down?”
This constant friction between development and operations became one of the biggest bottlenecks in software engineering.
That conflict gave birth to one of the most transformative movements in modern technology:
DevOps
Today, DevOps is no longer just about tools.
It is a culture. It is an engineering mindset. It is a delivery philosophy. And now, with AI entering infrastructure operations, DevOps is evolving again into what many call:
AIOps — Artificial Intelligence for IT Operations
In this blog, we will explore:
Why DevOps emerged
How software delivery evolved over decades
The CALMS philosophy
Traditional SDLC vs DevOps
The DevOps lifecycle and toolchain
DORA metrics for elite engineering teams
AI in DevOps and AIOps
Auto-remediation and self-healing infrastructure
Real-world enterprise challenges
The future of intelligent operations
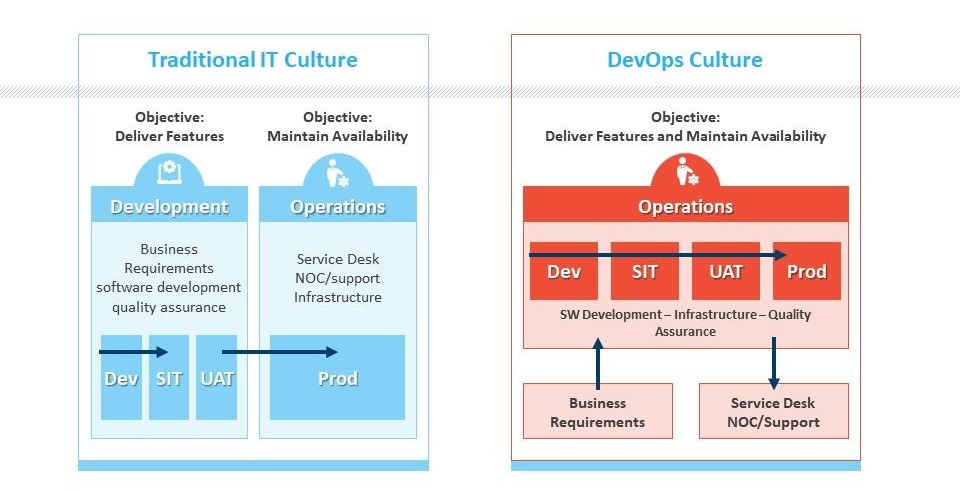
The Real Problem DevOps Was Born to Solve
Before DevOps, software teams largely worked in silos.
Typical structure:
Development Team
QA Team
Operations Team
Infrastructure Team
Each team worked independently.
This caused:
Delayed releases
Slow feedback loops
Frequent production failures
Deployment anxiety
Finger-pointing culture
Massive operational overhead
A developer’s goal was:
Deliver features quickly.
Operations teams had a different goal:
Maintain system stability.
Both objectives were important.
But they constantly clashed.
This conflict became the foundation for DevOps.
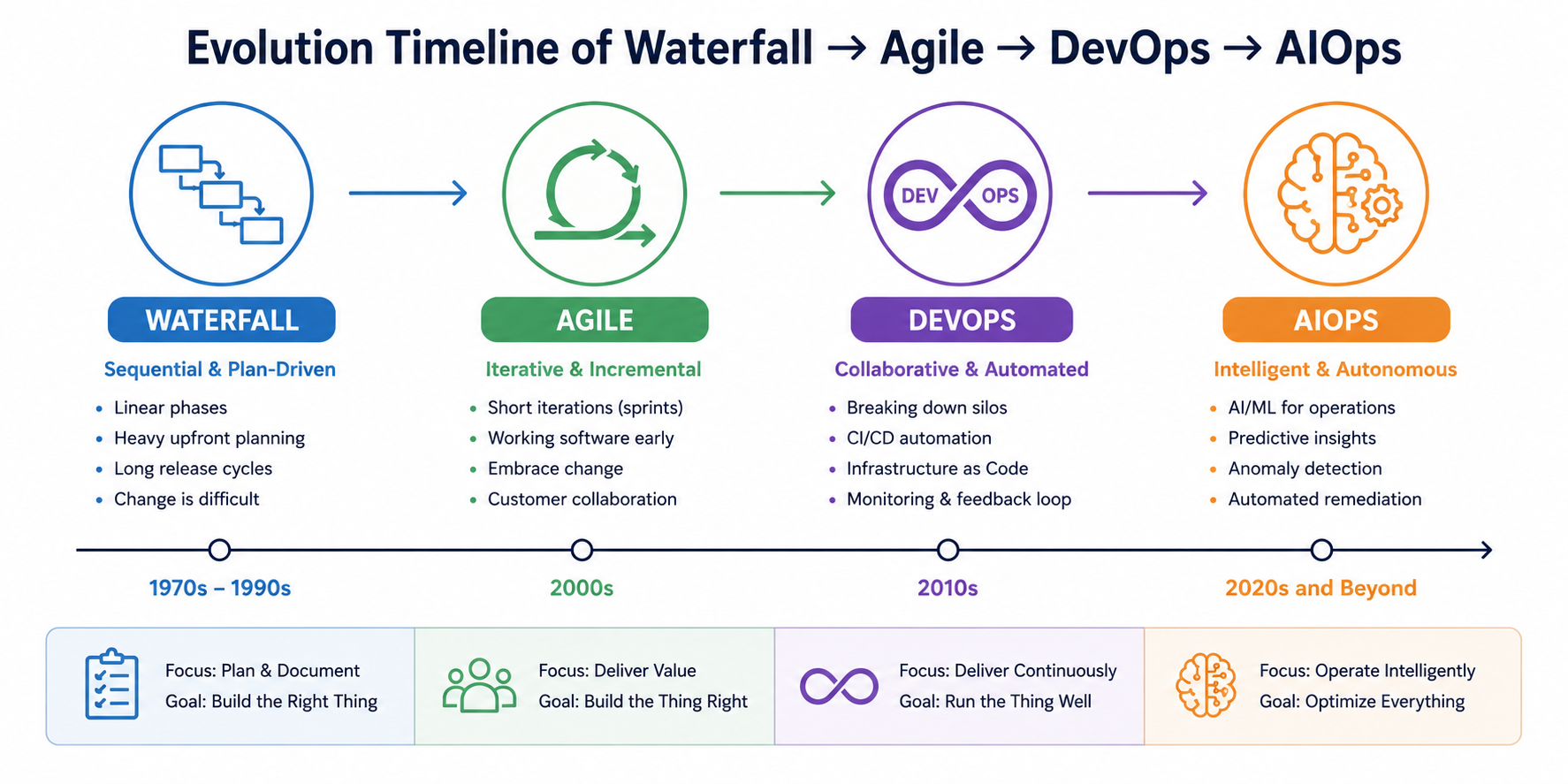
The Evolution of Software Delivery
1. Waterfall Era (1970s – 1990s)
The waterfall model followed a strict linear process:
Requirements → Design → Development → Testing → Deployment
Characteristics
Sequential execution
Heavy documentation
Long release cycles
Very slow feedback
Testing happened at the end
Biggest Problem
Bugs were discovered too late.
Fixing issues became extremely expensive.
2. Agile Revolution (2001)
The Agile Manifesto changed software development forever.
Instead of long release cycles, teams adopted:
Iterative development
Collaboration
Frequent feedback
Customer-centric delivery
Agile introduced the idea that:
Software should evolve continuously.
But Agile alone was not enough.
Developers became faster. Operations remained slow.
A new bottleneck appeared.
3. DevOps Emerges (2009)
In 2009, Patrick Debois organized the first DevOpsDays conference in Ghent.
This moment is widely considered the birth of DevOps.
The movement focused on:
Collaboration
Automation
Continuous delivery
Faster deployments
Shared ownership
One legendary book accelerated this movement:
The Phoenix Project
This book transformed DevOps from a technical idea into an engineering culture.
Visual Timeline of Software Evolution
1970s-1990s → Waterfall
2001 → Agile Manifesto
2009 → DevOps Movement
2013 → DORA Metrics
2016+ → SRE, Platform Engineering, Cloud Native
2020+ → AI-Augmented DevOps & AIOps
The CALMS Framework
One of the most important philosophical foundations of DevOps is:
CALMS
CALMS explains what successful DevOps organizations focus on.
C — Culture
Break silos.
Build shared ownership between:
Developers
QA
Operations
Security
Infrastructure
Teams win together. Teams fail together.
A — Automation
Automate repetitive manual tasks.
Examples:
CI/CD pipelines
Infrastructure provisioning
Monitoring
Testing
Deployments
Automation reduces:
Human error
Deployment delays
Operational overhead
L — Lean
Reduce waste.
Deliver in small batches.
Instead of deploying huge risky releases once every few months:
Deploy smaller, safer releases continuously.
M — Measurement
If you cannot measure it, You cannot improve it.
Modern engineering relies heavily on metrics.
Examples:
Deployment frequency
Failure rate
Recovery time
Lead time
S — Sharing
Knowledge must flow across teams.
Transparent communication is essential.
Documentation, monitoring dashboards, alerts, and postmortems should be shared.
Traditional SDLC vs DevOps
Traditional SDLC
DevOps
Teams work in silos
Cross-functional collaboration
Sequential workflow
Continuous delivery
Long release cycles
Frequent small releases
Testing at the end
Continuous automated testing
Slow feedback
Real-time feedback
High deployment risk
Incremental safer deployments
Manual operations
Automated pipelines
Late error detection
Early error detection
Why DevOps Improved Client Trust
In traditional models:
Projects could take months before showing results.
Clients had little visibility.
Delays created uncertainty.
In DevOps:
Working software is delivered quickly.
Features evolve incrementally.
Stakeholders see constant progress.
This dramatically improves:
Customer confidence
Delivery transparency
Business agility
DevOps Is Not Always the Right Answer
One important misconception:
DevOps does NOT replace everything.
Some industries still require:
Manual approvals
Manual provisioning
Compliance-driven workflows
Controlled infrastructure operations
Examples:
Banking
Healthcare
Government systems
Highly regulated enterprise environments
Automation must always respect compliance boundaries.
This is why experienced engineers must understand BOTH:
Automation
Manual operational processes
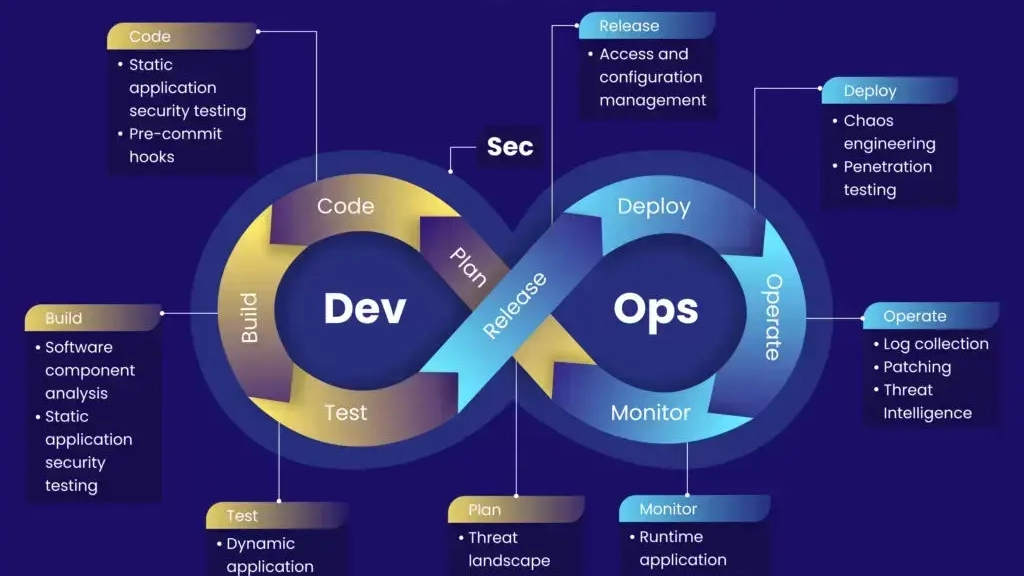
Understanding the DevOps Lifecycle
The DevOps lifecycle is often represented as an infinity loop.
Because tools evolve. Engineering fundamentals do not.
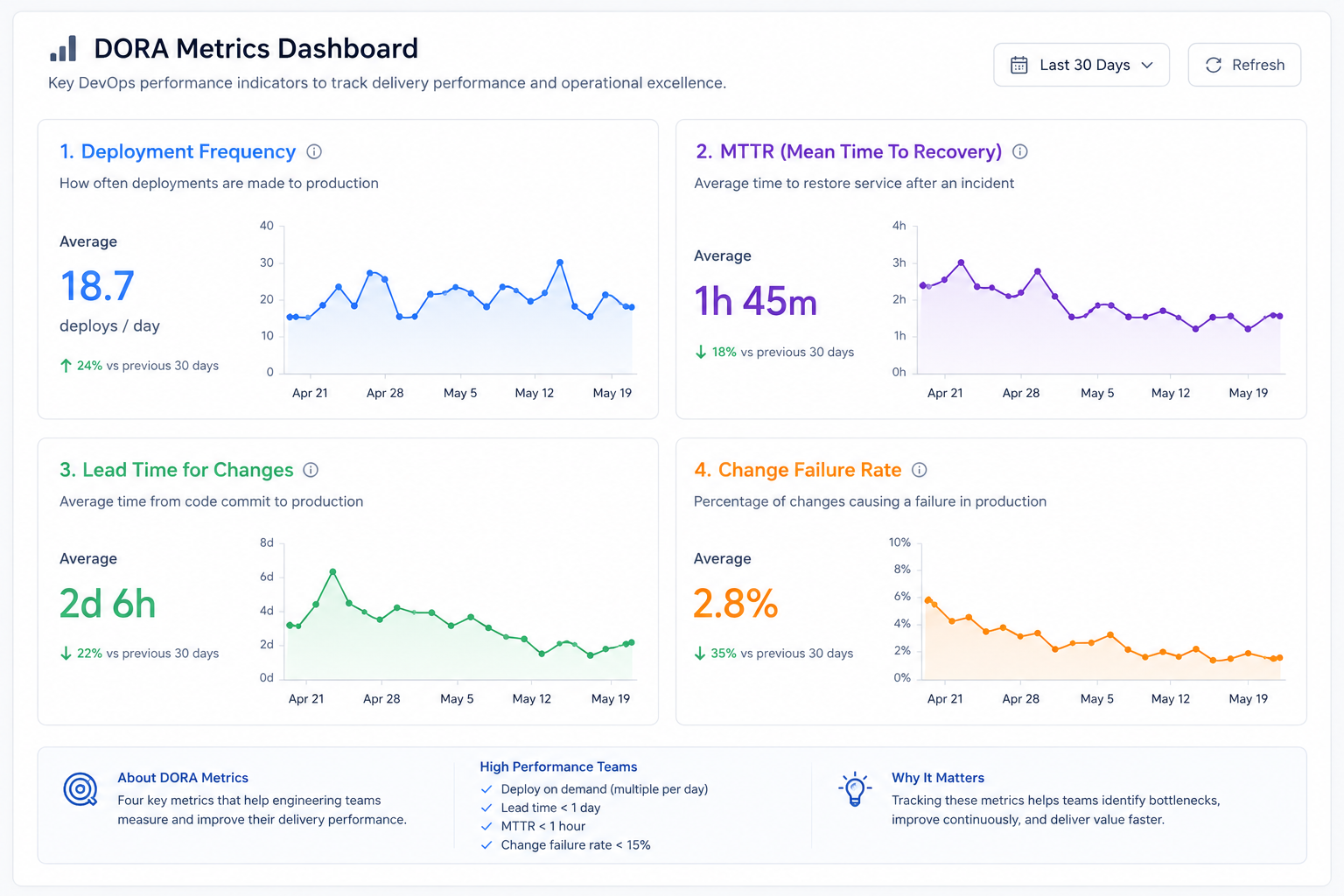
DORA Metrics — Measuring Engineering Excellence
In 2013, DORA (DevOps Research and Assessment) introduced four key metrics that became the global standard for measuring software delivery performance.
Google later helped popularize these metrics.
Even in 2024, DORA reports continue to show that elite engineering teams maintain strong performance during:
Layoffs
Budget cuts
Organizational instability
Because strong engineering culture scales.
The Four DORA Metrics
1. Deployment Frequency
How often code is deployed to production.
Elite teams:
Deploy multiple times per day
2. Lead Time for Changes
Time from code commit to production deployment.
Elite benchmark:
Less than 1 hour
3. Mean Time To Recovery (MTTR)
How quickly systems recover from incidents.
Elite benchmark:
Less than 1 hour
4. Change Failure Rate
Percentage of deployments causing failures.
Elite benchmark:
Between 0–15%
Why DORA Metrics Matter
These are NOT vanity metrics.
They are diagnostic metrics.
Example:
If your team:
Deploys once a month
Takes 3 days to recover from failures
Then DORA metrics immediately highlight where improvement is needed.
The Rise of AI in DevOps
Today, AI is influencing nearly every engineering domain.
DevOps is no exception.
However, the reality is important:
AI has not fully transformed DevOps yet.
Most enterprise systems still rely heavily on:
Rule-based automation
Traditional monitoring
Human-driven incident response
But AI is slowly enhancing operational intelligence.
Where AI Is Transforming DevOps
1. Code Generation
AI-powered coding assistants:
GitHub Copilot
Amazon CodeWhisperer
Cursor
Gemini-based coding tools
These tools improve developer productivity.
2. Predictive Failure Detection
Machine learning models analyze:
Logs
Metrics
Traffic patterns
Infrastructure telemetry
This helps predict risky deployments before failures occur.
3. Intelligent Alerting
Traditional monitoring creates noisy alerts.
AI systems help:
Reduce false positives
Prioritize incidents
Escalate intelligently
Recommend actions
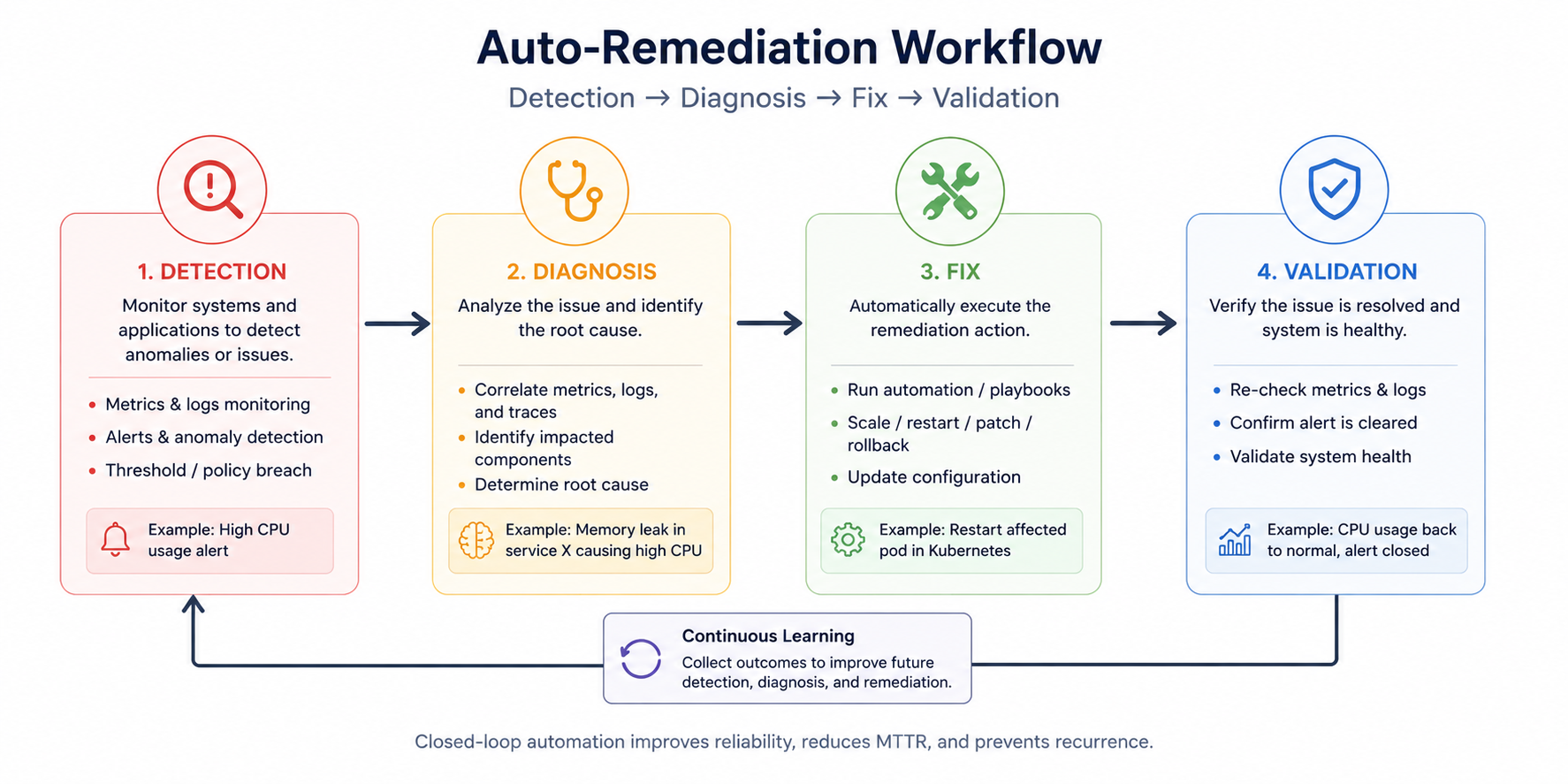
4. Auto-Remediation
This is one of the most exciting areas.
Systems automatically:
Detect issues
Diagnose root causes
Apply fixes
Validate recovery
Without human intervention.
Understanding Auto-Remediation
Auto-remediation means:
Systems can automatically detect and fix operational issues.
Examples:
Restart failed services
Replace unhealthy servers
Rotate leaked credentials
Block suspicious IPs
Patch vulnerabilities
Scale infrastructure
Auto-Remediation Workflow
Monitoring Detects Issue
↓
Alert Triggered
↓
Automation Playbook Executes
↓
Corrective Action Applied
↓
Validation Performed
↓
Incident Closed
Real-World Example: Secret Key Leak
Imagine a developer accidentally commits an AWS access key into GitHub.
Many beginners think:
“Just delete the key from GitHub.”
That is NOT enough.
Correct remediation:
Revoke the leaked key immediately
Rotate credentials
Remove the secret from the repository
Trigger repository protection policies
Audit system access
This is where automated remediation workflows become extremely valuable.
What Is AIOps?
AIOps stands for:
Artificial Intelligence for IT Operations
It adds an intelligence layer on top of traditional automation.
Traditional automation follows:
IF condition happens → Execute predefined script
AIOps goes beyond static rules.
It can:
Learn patterns
Predict incidents
Correlate events
Suggest root causes
Optimize remediation
Traditional Automation vs AIOps
Traditional Automation
AIOps
Rule-based
Learning-based
Reactive
Predictive
Static thresholds
Behavioral analysis
Limited context
Multi-signal intelligence
Manual RCA
Automated correlation
Simple scripts
Intelligent remediation
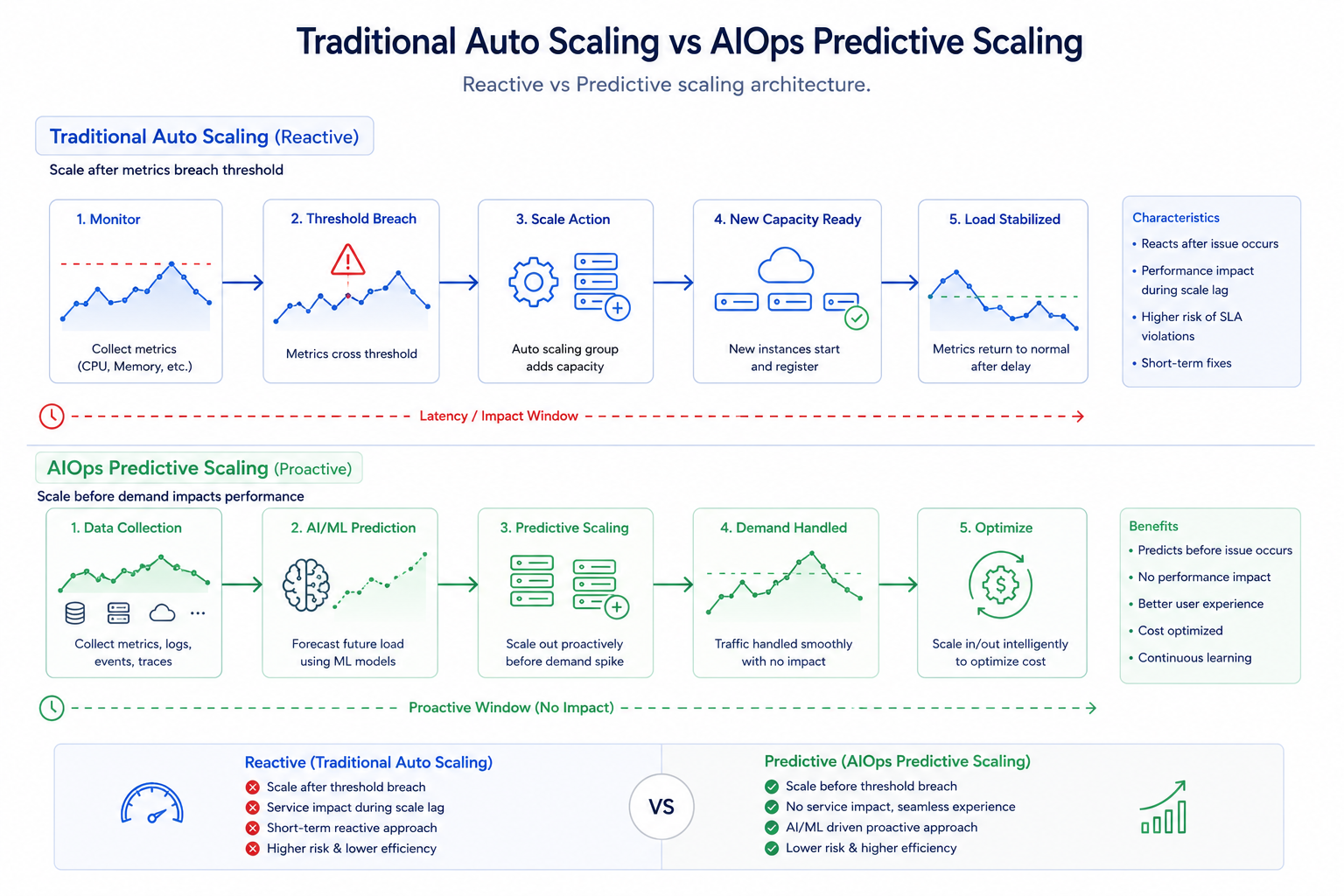
Example: CPU Spike Scenario
Traditional Auto Scaling
Typical rule:
IF CPU > 80% → Add more instances
Problem:
Scaling starts after the issue happens
Users already experience latency
No understanding of root cause
AIOps-Based Scaling
AIOps can:
Detect recurring traffic patterns
Predict spikes before they occur
Scale proactively
Correlate logs + traffic + errors
Avoid unnecessary scaling
Example:
If the system learns:
Traffic spikes every day at 9 AM
It can scale infrastructure BEFORE the spike occurs.
This improves:
User experience
Performance stability
Cost optimization
Intelligent Root Cause Analysis (RCA)
Traditional monitoring often shows symptoms.
Example:
High CPU
Increased latency
Error spikes
But engineers still need to investigate manually.
AIOps attempts to correlate:
Logs
Metrics
Infrastructure topology
Historical patterns
Traces
To identify the actual root cause.
Example: Nightly CPU Spike
Imagine a production server showing a recurring CPU spike every night at 2 AM.
Traditional operations:
Alerts open tickets repeatedly
Engineers manually investigate logs
Issue persists for weeks
AIOps approach:
Detect spike pattern
Capture process snapshots automatically
Identify offending process
Trigger remediation script
Kill problematic job automatically
This is the idea of:
Self-healing infrastructure
Why AIOps Is Still Evolving
Despite its promise, AIOps adoption is still limited.
Main reasons:
Compliance concerns
Data governance restrictions
AI hallucination risks
Lack of enterprise trust
Complex integration requirements
Industries like:
Banking
Healthcare
Government
Are extremely cautious.
Because infrastructure telemetry may contain sensitive information.
LLMs vs RAG Systems in Enterprise Operations
Many enterprises avoid directly using large LLMs in operational workflows.
Reason:
Hallucinations
LLMs can confidently provide incorrect outputs.
Instead, enterprises often prefer:
RAG (Retrieval-Augmented Generation)
RAG systems:
Work within constrained datasets
Use approved enterprise knowledge
Reduce hallucination risks
Improve operational reliability
This is particularly important in:
Security
Banking
Enterprise IT operations
The Future of DevOps
The future is moving toward:
Platform Engineering
SRE (Site Reliability Engineering)
AI-Augmented Operations
Intelligent Automation
Self-healing systems
But one thing remains constant:
Engineering fundamentals matter most.
Tools will evolve. Frameworks will evolve. AI systems will evolve.
But understanding:
System design
Monitoring
Reliability
Automation
Root cause analysis
Software delivery principles
Will always remain critical.
Final Thoughts
DevOps was never just about CI/CD pipelines.
It was about:
Breaking silos
Improving collaboration
Accelerating delivery
Building resilient systems
Creating shared ownership
Now, with AI entering operational workflows, we are witnessing the next evolution.
From:
Manual Operations
↓
Automated Operations
↓
Intelligent Operations
The journey from Waterfall → Agile → DevOps → AIOps reflects one core engineering truth:
The faster organizations learn, adapt, and automate responsibly, the more resilient they become.